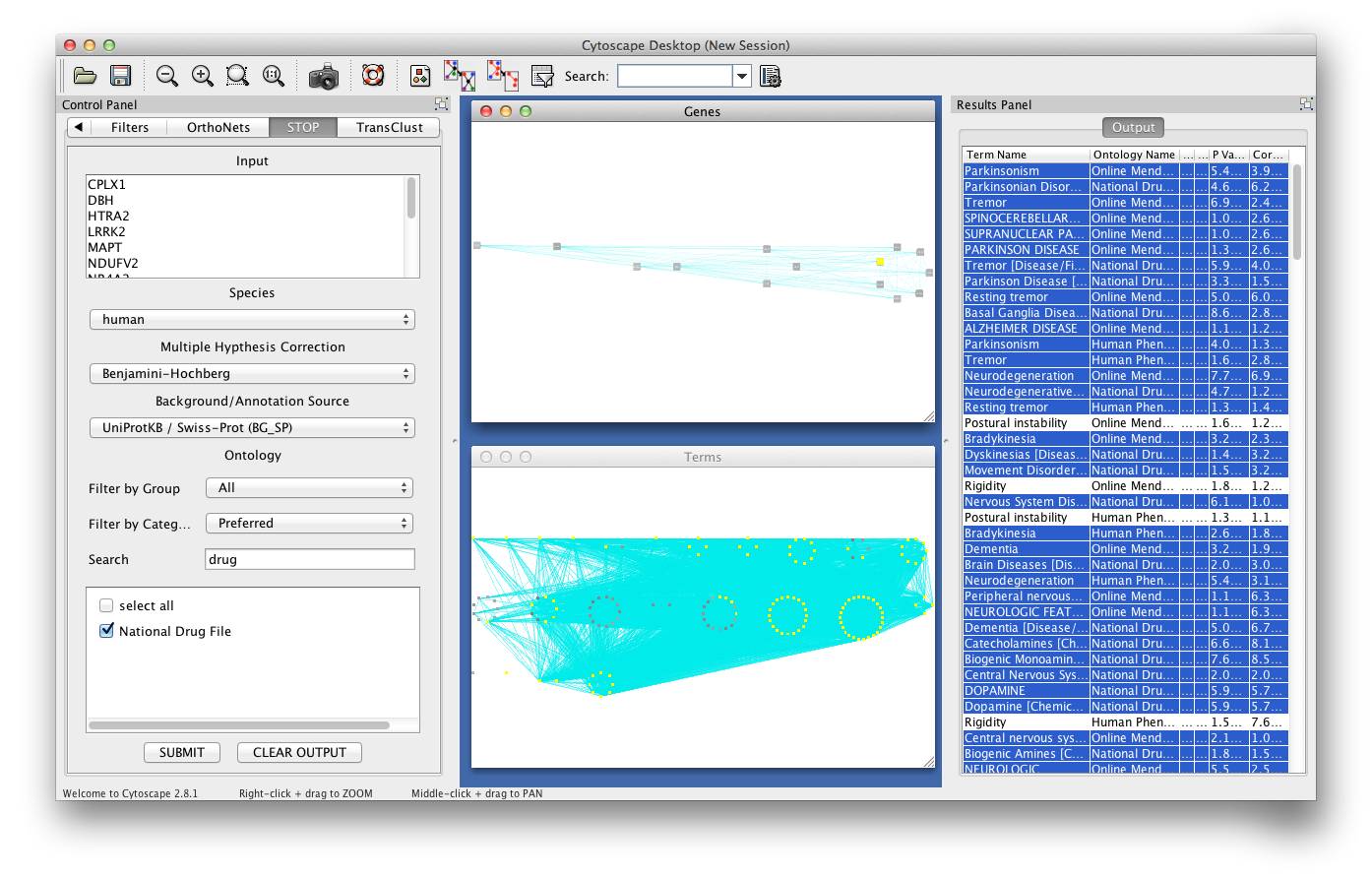
<p> <a href="http://www.mooneygroup.org/stop"> STOP</a> (Statistical tracking of ontological phrases) is a multi-ontology enrichment analysis tool. It is intended to be used to help from hypothesis about large sets of genes or proteins. The annotations used for enrichment analysis are obtained automatically applying text descriptions of genes and proteins to the <a href="http://bioportal.bioontology.org/annotator"> NCBO annotator</a>. Text for genes is found using NCBI Entrez Gene, and text for proteins is found using UniProt. The text is then run though NCBO annotator with all the available ontologies.<br><br> Given a list of genes a user may select up to 267 ontologies to be used for a term enrichment analysis (incl. OMIM, Human Phenotype Ontology, Gene Ontology, CHEBI,...). Two networks and a table will be created: a gene network with edges based on common enriched terms, a term network with edges based on common genes and the table of all enriched terms. These three entities are interacting with each other, i.e. selecting a term in the term network will highlight the respective genes and the term in the table etc.<br><br>For more details please visit <a href="http://www.mooneygroup.org/stop"> http://www.mooneygroup.org/stop </a>
<br><br>
Reference: <a href="http://www.biomedcentral.com/1471-2105/14/53/abstract">Wittkop T, TerAvest E, Evani US, Fleisch KM, Berman AE, Powell C, Shah NH, Mooney SD: STOP using just GO: a multi-ontology hypothesis generation tool for high throughput experimentation. BMC Bioinformatics 2013, 14:53.</a>
</p>