This app implements an algorithm (originally described by [http://www.cs.cmu.edu/~qyj/SuperComplex Qi et al]) for protein complex identification in PPI networks based on features specified in a Bayesian network structure.
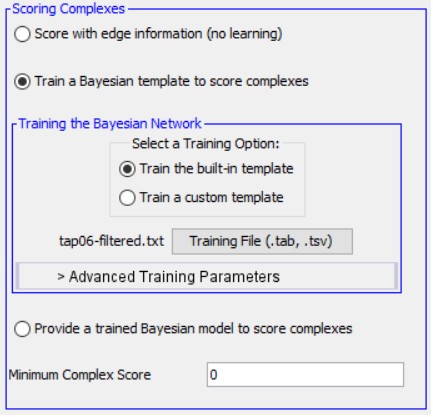
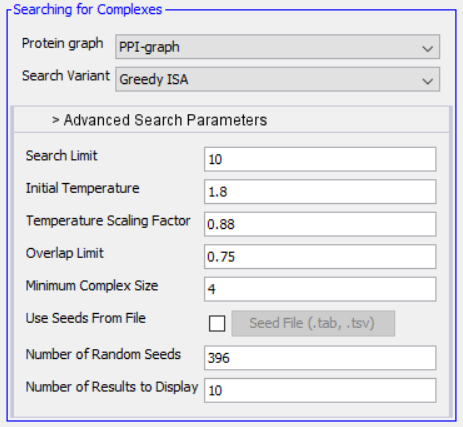
Using supervised learning, a Bayesian template may be trained with a list of known complexes and used to score candidates using real-valued data provided in the PPI graph. Candidate complexes are expanded according to one of three possible variants of iterative simulated annealing: Simple ISA, Greedy ISA, and Sorted-Neighbor ISA. For details on each of these search algorithms, see the [https://github.com/DataFusion4NetBio/Paper16-SCODE/blob/master/Demo/SCODEUserManual.pdf User Manual].
Resulting complexes may be evaluated to determine the app's performance using a user-provided set of testing complexes.
For more resources and sample files, check out the [https://github.com/DataFusion4NetBio/Paper16-SCODE/tree/master/Demo GitHub Demo folder].